Google I/O 2018, Google released the ML Kit development kit for developers to customize the mobile machine learning model, the core technology in the suite: Learn2Compress model compression technology, Google also quickly wrote an article on the Google AI and conducted a detailed introduction and actual testing. Here the compiled article from the Google official blog post.
Everyone knows that to successfully train and run deep learning models usually requires massive computing resources, large memory, and enough energy to support it. This also means that you want to run it successfully on both mobile and IoT devices. The model brings a corresponding obstacle. On-device machine learning allows you to run reasoning directly on the device and has the advantage of ensuring data privacy and ready use, regardless of network connectivity. Previous mobile machine learning systems, such as Lightweight Neural Networks MobileNets and ProjectionNets, addressed resource bottlenecks by optimizing model efficiencies. But what if you want to run your own design and training model in a mobile app on your phone?
Now that Google has solved this problem for you, on Google I/O 2018, Google has released the Mobile Terminal Machine Learning Development Kit- ML Kit for all mobile developers. An upcoming core feature in the ML Kit development kit is an automatic model compression service driven by the Learn2Compress technology developed by the Google research team. Learn2Compress technology can customize the mobile deep learning model in TensorFlow Lite. The customized model can run on the mobile device efficiently without worrying about memory shortage and slow running speed. Google is also pleased to implement Learn2Compress technology-driven image recognition in the ML Kit soon. Learn2Compress technology will be open to a small group of developers and will be available to more developers in the coming months. Developers who are interested in the technical features and are interested in designing their own models can click this URL (https://g.co/firebase/signup) to register.
Learn2Compress Technology Works
The Learn2Compress technology incorporates the learning frameworks such as ProjectionNet introduced in previous studies and incorporates several cutting-edge techniques for neural network model compression. Learn2Compress technology works like this: first, enter a user-provided pre-trained TensorFlow model, and then Learn2Compress technology starts training and optimizing the model, and automatically generates a ready-to-use mobile model, which is smaller in size and memory Occupancy and energy use are more efficient, and faster reasoning can be achieved with minimal loss of accuracy.

In order to achieve model compression, Learn2Compress technology uses multiple neural network optimizations and the following three model compression techniques:
- Reduce the model size by removing those weights or operations that do not have much effect on the prediction (such as low-scoring weights). This operation can especially improve the efficiency of the mobile-end model that contains sparse input or output. Although the model is compressed twice in size, it still retains 97% of the prediction quality of the original model.
- The quantized technique applied during the training of the model is particularly effective, and this technique can increase the speed of model inference by reducing the number of bits used for the model weight and the activation value. For example, using 8-bit fixed-point representations rather than floating-point values can speed model inference, reduce energy consumption, and promise to further reduce the model size by a factor of four.
- Joint training and distillation methods of the teacher-student learning strategy—guarantee the minimum loss of accuracy, Google is using a large network of teachers (in this case, using user-supplied TensorFlow model) to train a compressed student network (ie, on-device model).
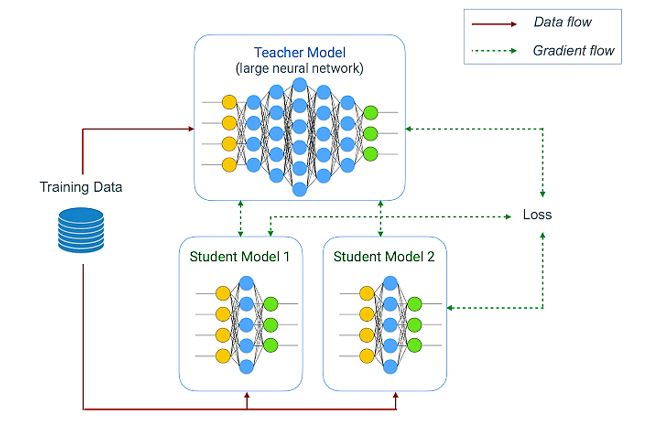
The teacher network can be fixed (as in the distillation method) or can be optimized together. The teacher network can even train multiple student models of different sizes at the same time. Therefore, Learn2Compress technology can generate multiple mobile models with different sizes and different inference speeds in a single operation, rather than a single model. It also supports developers to select the one that best meets their application requirements.
These and other technologies such as migration learning can also make the model compression process more efficient and scalable to large-scale data sets.
How does the performance of Learn2Compress technology perform?
In order to prove the effectiveness of Learn2Compress technology, Google works on several advanced deep neural networks used in image and natural language tasks (such as MobileNets, NASNet, Inception, ProjectionNet, etc.) and uses this technology to compress them into a mobile model… Given a task and data set, Google can use this technique to generate multiple mobile-side models with different inference speeds and model sizes.

In image recognition, Learn2Compress technology can generate both small and fast models that are suitable for mobile applications and have good prediction accuracy. For example, on ImageNet tasks, Learn2Compress technology can achieve a 22-times smaller model than Inception v3 baseline and a model 4 times smaller than MobileNet v1 baseline, and the accuracy rate is only reduced by 4.6-7%. On CIFAR-10, the time spent using the shared parameters to jointly train multiple Learn2Compress models is only 10% longer than training a single Learn2Compress large model. For example, the yields 3 compression model is 94 times smaller in size. It is 27 times faster and the cost is reduced by 36 times, and it can achieve good prediction quality (90-95% top-1 level accuracy).

Google is also very happy to see that developers have used this technology to make some achievements. For example, a fishing enthusiast social platform called Fishbrain uses Google’s Learn2Compress technology to compress the platform’s current image recognition cloud model (80MB+, 91.8% top-3 accuracy) into a very small one. Mobile model (less than 5MB in size but still maintaining similar accuracy to the original large model). In other cases, Google discovered that thanks to the regularization effect, the compressed model may even have slightly better accuracy than the original large model.
Google said that with the continuous development of machine learning and deep learning technologies, they will continue to improve the Learn2Compress technology and extend it to more user cases (not limited to such models as image recognition). Google is also looking forward to launching the model compression cloud service for ML Kit. Google hopes that Learn2Compress technology can help developers automatically build and optimize their own mobile machine learning models so that developers can focus on developing excellent applications and cool applications that include computer vision, natural language, and other machine learning applications.
Related Posts
How to create QR codes on Google Sheets for URLs or any other text elements
How to set Gemini by Google as the default Android assistant
Finding Visual Studio Code Version on Windows 11 or 10
Running PHP Files in Visual Studio Code with XAMPP: A Step-by-Step Guide
Multiple Methods to Verify Python Installation on Windows 11
Single Command to install Android studio on Windows 11 or 10