NoSql, it stands for Not Only SQL, refers to the non-relational database. The next generation database mainly addresses several key points: non-relational, distributed, open source, and horizontally scalable. The non-relational database has developed very rapidly due to its own characteristics. The NoSQL database was created to solve the challenges brought by the multiple data types of large-scale data collection, especially the big data application problem. It also supports easy replication, simple APIs, final consistency (non-ACID), and large data. It is stored by us with the most key-values, and of course other document types, column stores, graph databases, XML databases, and so on. Here are some top available NoSQL database programs in Open source or free category.
Note: This article only listing the NoSQL database programs available online, we haven’t reviewed, so we can’t say which NoSQL database is best to what scenario.
Oracle NoSQL Database
Oracle NoSQL Database is an open source non-SQL distributed the key-value database. Developed by Oracle Corporation. In short, it is known as OND that uses the Oracle Berkeley DB Java Edition high-availability storage engine. This Oracle’s NoSQL Database program is a client-server, sharded, sharded-noting system that provides single-master, multi-replica database replication. It can be used to provide latency-sensitive applications and services suited for a large volume. It features Horizontal scalability, Sharding and replication; High availability and fault-tolerance; Transparent load balancing, Elastic configuration, Multi-zone deployment, JSON data format, Online rolling upgrade, ACID compliant transaction and more. It has two editions one is Oracle NoSQL Database Server Community Edition under an Apache License, Version 2.0 and the other one is Enterprise Edition under the Oracle Commercial License
To download and know more about Oracle NoSQL Database (ODM) visit its official website.
MongoDB
MongoDB is a database based on distributed file storage. By the C ++ written language. Designed to provide scalable, high-performance data storage solutions for web applications.
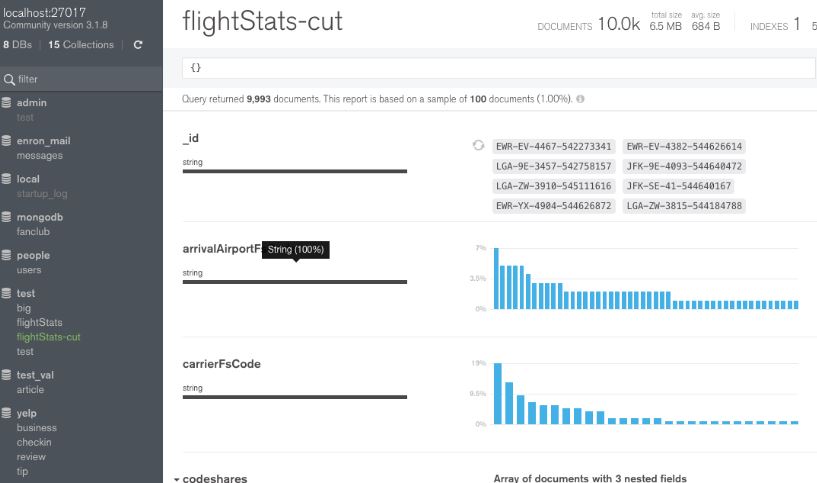
MongoDB is a product between a relational database and a non-relational database. It is the most versatile and most relational database in a non-relational database. It supports input of data is very taken flexible manner, the scheme is very much similar to JSON format so it can store more complex data types. The biggest feature of Mongo is that it supports a very powerful query language. Its syntax is similar to the object-oriented query language. It can perform almost all the functions of relational database single-table query, and also supports indexing data. MongoDB is available in three versions Community (free), Enterprise (subscription based) and Atlas available as an on-demand fully managed service. Its core features are Ad hoc queries, Indexing, Replication, Load balancing, File storage, Aggregation, Server-side JavaScript execution, Capped collections and Transactions.
Here is the link to Download community version for Windows, Linux or MacOS.
Apache Cassandra
Cassandra is a hybrid, a NoSQL database program similar to Google’s BigTable. The main feature of Cassandra is that it is not a database, but a distributed network service composed of a bunch of database nodes. A write operation to Cassandra will be copied to other nodes, and the read operation of Cassandra will also be Route to a node to read. For a Cassandra cluster, scaling performance is a relatively simple matter, just add nodes to the cluster.
Cassandra’s main features are richer than Dynamo (distributed Key-Value storage system), but the support is not as good as document storage MongoDB (an open source product between relational and non-relational databases, the most versatile of non-relational databases).
Cassandra was originally developed by Facebook and later turned into an open source project. It is an ideal database for social networking cloud computing. It features- No single point of failure as data is distributed across the cluster; Supports replication and multi-data centre replication; Horizontal scalability, Fault-tolerant, Tunable consistency, MapReduce support, Cassandra Query Language (CQL); management and monitoring via Java Management Extensions (JMX) and more…
Download Apache Cassandra from here
Redis

Redis acronym that stands for Remote Dictionary Server which one of the most popular NoSQL database programs. It is an in-memory key-value database with a built-in net interface written in ANSI-C for Posix systems. There are also some opinions that Redis is a memory database because its high performance is based on the basis of memory operations. Others think that Redis is a data structure server because Redis supports complex data features such as List, Set, HyperLogLogs, bitmaps, streams, spatial indexes and so on. However, the role of Redis determined by how you use it. Redis is an open source NoSQL database and free to use.
Apache CouchDB
CouchDB is an open source, document-oriented NoSQL database program accessible through the RESTful JavaScript Object Notation (JSON) API. The term “Couch” is an acronym for “Cluster Of Unreliable Commodity Hardware”, which reflects CouchDB’s goal of being highly scalable, providing high availability and high reliability, even on hardware that is prone to failure. CouchDB was originally written in C++, but in April 2008, the project moved to the Erlang OTP (programming language-wiki) for concurrency, distribution and fault tolerance.
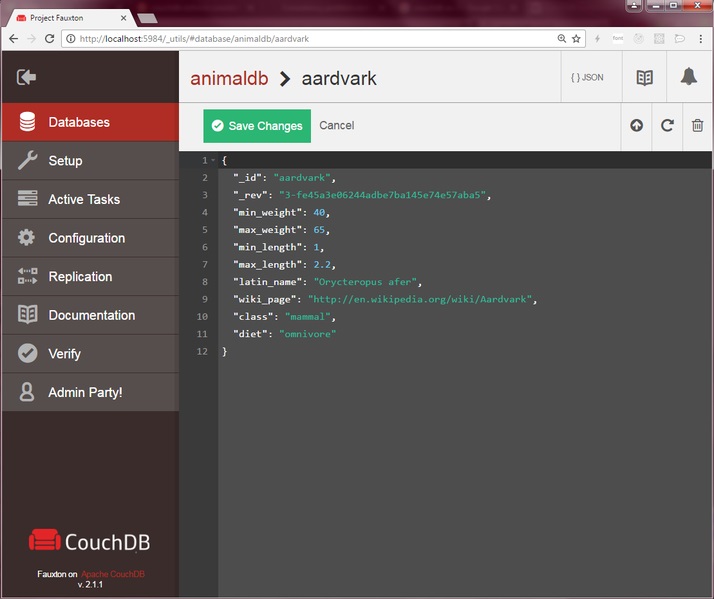
Its data storage method is somewhat similar to Lucene ‘s index file format. The biggest significance of CouchDB is that it is a new generation storage system for web applications. CouchDB implements a form of multi-version concurrency control (MVCC) so it does not lock the database file during writes. Conflicts are left to the application to resolve. CouchDB is built on top of a powerful B-tree storage engine; it is responsible for sorting the data in CouchDB and provides a mechanism for performing a search, insert, and delete operations within the log-sharing time. CouchDB uses this engine for all internal data, documents, and views.
The Map/Reduce feature in CouchDB generates key/value pairs, and CouchDB inserts them into the B-tree engine and sorts them according to their keys. This enables efficient lookups with keys and improves the performance of operations in the B-tree. In addition, this means that data can be partitioned across multiple nodes without having to query each node individually.
Couchbase NoSQL Database Program
Couchbase Server (formerly Membase) is a document-oriented NoSQL database management system that combines the simplicity and reliability of CouchDB with the high performance of Memcached and the scalability of Membase. It is also an open source NoSQL Database program that uses shared-nothing or distributed architecture. It is highly optimized for interactive applications, which allows it to serve simultaneously creating, storing, retrieving, aggregating, manipulating and presenting of data.
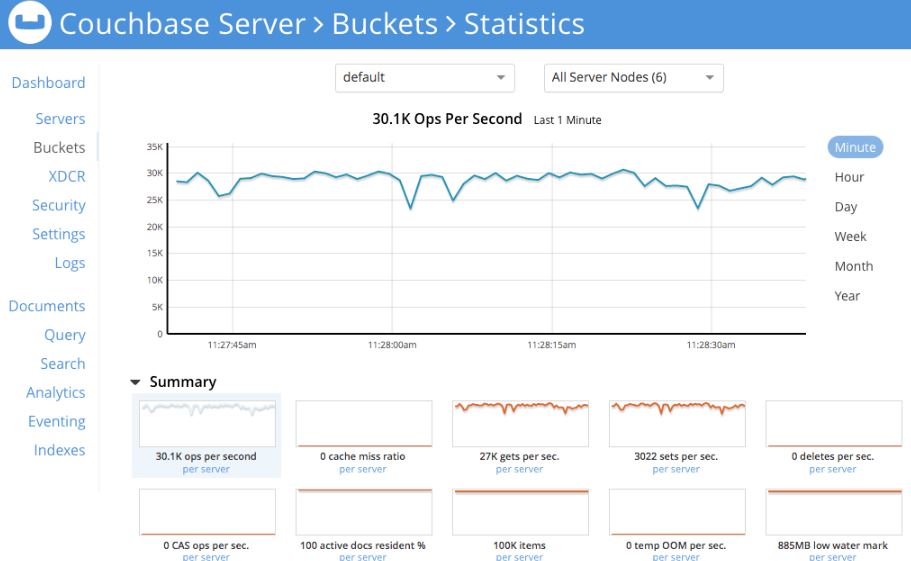
The administrators can deploy it to cluster from a single machine to multiple. Furthermore,easy-to-scale key-value or JSON document access with low latency and high sustained throughput.
It is available in multiple forms Couchbase server, Couchbase Mobile and as integrations. Plus, it is available in both community and enterprise solutions for Windows and Linux servers.
Riak (ree-ack) NoSQL Database

Riak is another NoSQL database program which also has an open source version along with an enterprise and a cloud storage version. With high availability and scalability goal this distributed data store system written in Erlang language like CouchDB. Riak’s implementation is based on Amazon’s Dynamo paper. Riak supports systems built with multiple nodes, and each read and writes request does not require the participation of all nodes in the cluster. Provides a flexible map/reduce engine, a friendly HTTP/JSON query interface.
Riak is very easy to deploy and scale. Additional nodes can be added seamlessly to the cluster. Features such as link walking and support for Map/Reduce allow for more complex queries. In addition to the HTTP API, Riak also provides a native Erlang API and support for Protocol Buffer.
There are currently three ways to access Riak: HTTP API (RESTful interface), Protocol Buffers, and a native Erlang interface. The API supports common HTTP methods: GET, PUT, POST, DELETE, which are used to retrieve, update, create, and delete objects, respectively.
Core features it offers are Fault-tolerant availability, Queries support, Predictable latency, Keys/values can be stored in memory, disk, or both; Multi-datacenter replication and Tunable consistency; Amason S3 Compatibility, Integration with Apache Spark, Apache Solar, Apache Mesos, Redis Caching.
OrientDB: Graph Database
OrientDB is an open source NoSQL database which is multi-model and supports native graphics, document full text, responsiveness, document, key/value, and object-oriented. It is written in Java and is very fast: on regular hardware, it can store 220,000 records per second. For document databases, it also supports ACID transaction processing.
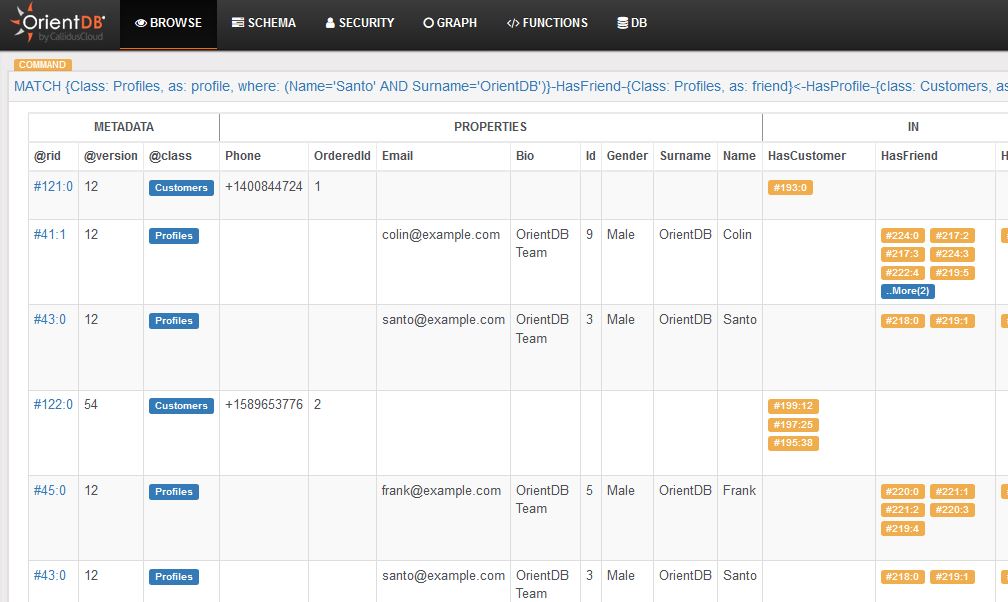
Without expensive runtime JOINs, connections can be managed as persistent pointers between records. You can iterate through thousands of records in a matter of milliseconds.
OrientDB supports schema-less, schema-full, and schema-mixed modes, with a powerful security analysis system based on users and roles, and supports SQL between query languages.
It features quick installation less than in 60 seconds (claimed by its developer), Graph structured data model; open source graph computing framework; supports SQL queries with extensions; native support to HTTP, RESTful protocol, and JSON additional libraries or components; multi-master replication including geographically distributed clusters; can run on Linux, OS X, Windows, or any system with a compliant JVM; Full server takes only 512 MB of footprint; Cloud read and more… Community and enterprise both are available.
Apache HBase
HBase – Hadoop Database is an open source non-relational high-reliability, high-performance, column-oriented, a scalable distributed storage system that uses HBase technology to build large-scale structured storage clusters on inexpensive PC Servers.

HBase is an open source implementation of Google Bigtable. Similar to Google Bigtable, which uses GFS as its file storage system, HBase uses Hadoop HDFS as its file storage system. Google runs MapReduce to process massive data in Bigtable. HBase also uses Hadoop MapReduce to process HBase. Massive data; Google Bigtable uses Chubby as a collaborative service, and HBase uses Zookeeper as a counterpart.
ArangoDB
ArangoDB is a native multi-model database that combines key/value key/value pairs, graph graphs, and document data models. It provides a unified database query language covering three data models and allows for a mix of three in a single query. model. Based on its native integrated multi-model feature, you can build high-performance programs, and all three data models support horizontal scaling. Offers both Community and Enterprise versions.
Other Useful Resources to read:
- 6 Top open source team chat software for self-hosted environment
- 6 Important SQL Commands That Every Programmer Should be Aware of
- 10 Top Mongodb GUI tools to manage databases graphically
- How to install MySQL Workbench on Ubuntu
Note: Article is contributed by Guest Author – Kanika Marlean
Related Posts
How to Install SQL Server Express on Windows 11 using PowerShell or CMD
How to install only PSQL client in Windows 11 or 10?
10 data management mistakes we commonly see
What is Pandas Read SQL?
PopSQL Editor Software Review: Write queries, visualize data, and share results
How to Make Money as a Data Scientist through Alternate Sources